Haskell and functional programming
Enjoy learning haskell but not only haskell.
Haskell Introduction
In this course we use Haskell, because it is the most widespread language with good support for mathematically structured programming.
1 | f :: Int -> Bool |
First $x$ is the input and the RHS of the equation is the Output.
Currying
In mathematics, we treat $log_{10}(x)$ and $log_2 (x)$ and ln(x) as separate functions.
In Haskell, we have a single function logBase that, given a number n, produces a function for $log_n(x)$
1 | log10 :: Double -> Double |
Function application associates to the left in Haskell, so:
logBase 2 64 ≡ (logBase 2) 64
Functions of more than one argument are usually written this way in Haskell, but it is possible to use tuples instead…
Tuples
Tuples are another way to take multiple inputs or produce multiple outputs:
1 | toCartesian :: (Double, Double) -> (Double, Double) |
N.B: The order of bindings doesn’t matter. Haskell functions have no side effects, they just return a result. There’s no notion of time(no notion of sth happen before sth else).
Higher Order Functions
In addition to returning functions, functions can take other functions as arguments:
1 | twice :: (a -> a) -> (a -> a) |
Haskell concrete types are written in upper case like Int, Bool, and in lower case if they stand for any type.
1 | {- |
Lists
Haskell makes extensive use of lists, constructed using square brackets. Each list element must be of the same type.
1 | [True, False, True] :: [Bool] |
Map
A useful function is map, which, given a function, applies it to each element of a list:
1 | map not [True, False, True] = [False, True, False] |
The last example here uses a lambda expression to define a one-use function without giving it a name.
What’s the type of map?
1 | map :: (a -> b) -> [a] -> [b] |
Strings
The type String in Haskell is just a list of characters:
1 | type String = [Char] |
This is a type synonym, like a typedef in C.
Thus: "hi!" == ['h', 'i', '!']
Practice
Word Frequencies
Given a number $n$ and a string $s$, generate a report (in String form) that lists the $n$ most common words in the string $s$.
We must:
- Break the input string into words.
- Convert the words to lowercase.
- Sort the words.
- Count adjacent runs of the same word.
- Sort by size of the run.
- Take the first $n$ runs in the sorted list.
- Generate a report.
1 | import Data.Char(toLower) |
Functional Composition
We used function composition to combine our functions together. The mathematical $(f ◦ g)(x)$ is written $(f . g) x$ in Haskell.
In Haskell, operators like function composition are themselves functions. You can define your own!
1 | -- Vector addition |
You could even have defined function composition yourself if it didn’t already exist:
1 | (.) :: (b -> c) -> (a -> b) -> (a -> c) |
Lists
How were all of those list functions we just used implemented?
Lists are singly-linked lists in Haskell.
The empty list is written as [] and a list node is written as x : xs.
The value x is called the head and the rest of the list xs is called the tail. Thus:
1 | "hi!" == ['h', 'i', '!'] == 'h':('i':('!':[])) |
When we define recursive functions on lists, we use the last form for pattern matching:
1 | map :: (a -> b) -> [a] -> [b] |
We can evaluate programs equationally:
1 | {- |
List Functions
1 | -- in maths: f(g(x)) == (f o g)(x) |
Induction
Suppose we want to prove that a property $P(n)$ holds for all natural numbers $n$. Remember that the set of natural numbers $N$ can be defined as follows:
Definition of Natural Numbers
Inductive definition of Natural numbers
- 0 is a natural number.
- For any natural number $n, n + 1$ is also a natural number
Therefore, to show $P(n)$ for all $n$, it suffices to show:
$P(0)$ (the base case), and
assuming $P(k)$ (the inductive hypothesis),
$⇒ P(k + 1)$ (the inductive case).
Induction on Lists
Haskell lists can be defined similarly to natural numbers
Definition of Haskell Lists
- [] is a list.
- For any list xs, x:xs is also a list (for any item x).
This means, if we want to prove that a property P(ls) holds for all lists ls, it suffices to show:
- P([]) (the base case)
- P(x:xs) for all items x, assuming the inductive hypothesis P(xs)
Data Types
So far, we have seen type synonyms using the type keyword. For a graphics library, we might define:
1 | type Point = (Float, Float) |
But these definitions allow Points and Vectors to be used interchangeably, increasing the likelihood of errors.
We can define our own compound types using the data keyword:
1 | data Point = Point Float Float |
First Point is the type name
Second Point is Constructor name
Floats are Constructor argument types
1 | data Vector = Vector Float Float |
Records
We could define Colour similarly:
1 | data Colour = Colour Int Int Int Int |
But this has so many parameters, it’s hard to tell which is which. Haskell lets us declare these types as records, which is identical to the declaration style on the previous slide, but also gives us projection functions and record syntax:
1 | data Colour = Colour { redC :: Int |
Here, the code redC (Colour 255 128 0 255) gives 255.
Enumeration Types
Similar to enums in C and Java, we can define types to have one of a set of predefined values:
1 | data LineStyle = Solid |
Types with more than one constructor are called sum types
Algebraic Data Types
Just as the Point constructor took two Float arguments, constructors for sum types can take parameters too, allowing us to model different kinds of shape:
1 | data PictureObject |
Recursive and Parametric Types
Data types can also be defined with parameters, such as the well known Maybe type, defined in the standard library:
1 | data Maybe a = Just a | Nothing |
Types can also be recursive. If lists weren’t already defined in the standard library, we could define them ourselves:
1 | data List a = Nil | Cons a (List a) |
We can even define natural numbers, where 2 is encoded as Succ(Succ Zero):
1 | data Natural = Zero | Succ Natural |
Types in Design
Make illegal states unrepresentable.
– Yaron Minsky (of Jane Street)
Choose types that constrain your implementation as much as possible. Then failure scenarios are eliminated automatically.
Partial Functions
A partial function is a function not defined for all possible inputs.
Partial functions are to be avoided, because they cause your program to crash if undefined cases are encountered. To eliminate partiality, we must either:
enlarge the codomain, usually with a
Maybetype:1
2
3safeHead :: [a] -> Maybe a
safeHead (x:xs) = Just x
safeHead [] = Nothingconstrain the domain to be more specific:
1
2
3
4safeHead' :: NonEmpty a -> a
safeHead' (One a) = a
safeHead' (Cons a _) = a
data NonEmpty a = One a | Cons a (NonEmpty a)
Type Classes
You have already seen functions such as: compare, (==), (+), (show)
that work on multiple types, and their corresponding constraints on type variables Ord, Eq, Num and Show.
These constraints are called type classes, and can be thought of as a set of types for which certain operations are implemented.
Show
The Show type class is a set of types that can be converted to strings.
1 | class Show a where -- nothing to do with OOP |
Types are added to the type class as an instance like so:
1 | instance Show Bool where |
We can also define instances that depend on other instances:
1 | instance Show a => Show (Maybe a) where |
Fortunately for us, Haskell supports automatically deriving instances for some classes, including Show.
Read
Type classes can also overload based on the type returned.
1 | class Read a where |
Semigroup
A semigroup is a pair of a set S and an operation • : S → S → S where the operation
- s associative.
Associativity is defined as, for all a, b, c:
(a • (b • c)) = ((a • b) • c)
Haskell has a type class for semigroups! The associativity law is enforced only by programmer discipline:
1 | class Semigroup s where |
What instances can you think of? Lists & ++, numbers and +, numbers and *
Example:
Lets implement additive colour mixing:
1 | instance Semigroup Colour where |
Observe that associativity is satisfied.
Moniod
A monoid is a semigroup (S, •) equipped with a special identity element z : S such that x • z = x and z • y = y for all x, y.
1 | class (Semigroup a) => Monoid a where |
For each of the semigroups discussed previously(lists, num and +, num and *):
- Are they monoids? Yes
- If so, what is the identity element? [], 0, 1
Are there any semigroups that are not monoids? Maximum
Newtypes
There are multiple possible monoid instances for numeric types like Integer:
- The operation (+) is associative, with identity element 0
- The operation (*) is associative, with identity element 1
Haskell doesn’t use any of these, because there can be only one instance per type per class in the entire program (including all dependencies and libraries used).
A common technique is to define a separate type that is represented identically to the original type, but can have its own, different type class instances.
In Haskell, this is done with the newtype keyword.
A newtype declaration is much like a data declaration except that there can be only one constructor and it must take exactly one argument:
1 | newtype Score = S Integer |
Here, Score is represented identically to Integer, and thus no performance penalty is incurred to convert between them.
In general, newtypes are a great way to prevent mistakes. Use them frequently!
Ord
Ord is a type class for inequality comparison
1 | class Ord a where |
What laws should instances satisfy?
For all x, y, and z:
- Reflexivity: x <= x
- Transitivity: If x <= y and y <= z then x <= z
- Antisymmetry: If x <= y and y <= x then x == y.
- Totality: Either x <= y or y <= x
Relations that satisfy these four properties are called total orders(most are total orders). Without the fourth (totality), they are called partial orders(e.g. division).
Eq
Eq is a type class for equality or equivalence
1 | class Eq a where |
What laws should instances satisfy?
For all x, y, and z:
- Reflexivity: x == x.
- Transitivity: If x == y and y == z then x == z.
- Symmetry: If x == y then y == x.
Relations that satisfy these are called equivalence relations.
Some argue that the Eq class should be only for equality, requiring stricter laws like:
If x == y then f x == f y for all functions f
But this is debated.
Funtors
Types and Values
Haskell is actually comprised of two languages.
- The value-level language, consisting of expressions such as if, let, 3 etc.
- The type-level language, consisting of types Int, Bool, synonyms like String, and type constructors like Maybe, (->), [ ] etc
This type level language itself has a type system!
Kinds
Just as terms in the value level language are given types, terms in the type level language are given kinds.
The most basic kind is written as *.
- Types such as Int and Bool have kind *.
- Seeing as Maybe is parameterised by one argument, Maybe has kind * -> *: given a type (e.g. Int), it will return a type (Maybe Int).
Lists
Suppose we have a function:
1 | toString :: Int -> String |
And we also have a function to give us some numbers:
1 | getNumbers :: Seed -> [Int] |
How can I compose toString with getNumbers to get a function f of type Seed -> [String]?
we use map: f = map toString . getNumbers.
What about return a Maybe Int? we can use maybe map
1 | maybeMap :: (a -> b) -> Maybe a -> Maybe b |
We can generalise this using functor.
Functor
All of these functions are in the interface of a single type class, called Functor.
1 | class Functor f where |
Unlike previous type classes we’ve seen like Ord and Semigroup, Functor is over types of kind * -> *.
1 | -- Instance for tuples |
Functor Laws
The functor type class must obey two laws:
- fmap id == id(indentity law)
- fmap f . fmap g == fmap (f . g)(composition law, haskell use this law to do optimisation)
In Haskell’s type system it’s impossible to make a total fmap function that satisfies the first law but violates the second.
This is due to parametricity.
Property Based Testing
Free Properties
Haskell already ensures certain properties automatically with its language design and type system.
- Memory is accessed where and when it is safe and permitted to be accessed (memory safety).
- Values of a certain static type will actually have that type at run time.
- Programs that are well-typed will not lead to undefined behaviour (type safety).
- All functions are pure: Programs won’t have side effects not declared in the type. (purely functional programming)
⇒ Most of our properties focus on the logic of our program.
Logical Properties
We have already seen a few examples of logical properties.
Example:
- reverse is an involution: reverse (reverse xs) == xs
- right identity for (++): xs ++ [] == xs
- transitivity of (>): (a > b) ∧ (b > c) ⇒ (a > c)
The set of properties that capture all of our requirements for our program is called the functional correctness specification of our software.
This defines what it means for software to be correct.
Proofs
Last week we saw some proof methods for Haskell programs. We could prove that our implementation meets its functional correctness specification.
Such proofs certainly offer a high degree of assurance, but:
- Proofs must make some assumptions about the environment and the semantics of the software.
- Proof complexity grows with implementation complexity, sometimes drastically.
- If software is incorrect, a proof attempt might simply become stuck: we do not always get constructive negative feedback.
- Proofs can be labour and time intensive ($$$), or require highly specialised knowledge ($$$).
Testing
Compared to proofs:
- Tests typically run the actual program, so requires fewer assumptions about the language semantics or operating environment.
- Test complexity does not grow with implementation complexity, so long as the specification is unchanged.
- Incorrect software when tested leads to immediate, debuggable counter examples.
- Testing is typically cheaper and faster than proving.
- Tests care about efficiency and computability, unlike proofs(e.g. termination is provable but not computable).
We lose some assurance, but gain some convenience ($$$).
Property Based Testing
Key idea: Generate random input values, and test properties by running them.
Example(QuickCheck Property)
1 | import Test.QuickCheck |
PBT vs. Unit Testing
Properties are more compact than unit tests, and describe more cases.
⇒ Less testing code
Property-based testing heavily depends on test data generation:
Random inputs may not be as informative as hand-crafted inputs
⇒ use shrinking(When a test fails, it finds the smallest test case still falls)
Random inputs may not cover all necessary corner cases:
⇒ use a coverage checker
Random inputs must be generated for user-defined types:
⇒ QuickCheck includes functions to build custom generators
By increasing the number of random inputs, we improve code coverage in PBT.
Test Data Generation
Data which can be generated randomly is represented by the following type class:
1 | class Arbitrary a where |
Most of the types we have seen so far implement Arbitrary.
Shrinking
The shrink function is for when test cases fail. If a given input x fails, QuickCheck will try all inputs in shrink x; repeating the process until the smallest possible input is found
Testable Types
The type of the quickCheck function is:
1 | -- more on IO later |
The Testable type class is the class of things that can be converted into properties. This includes:
Bool values
QuickCheck’s built-in Property type
Any function from an Arbitrary input to a Testable output:
1
2instance (Arbitrary i, Testable o)
=> Testable (i -> o) ...
Thus the type [Int] -> [Int] -> Bool (as used earlier) is Testable.
Examples
1 | split :: [a] -> ([a],[a]) |
Redundant Properties
Some properties are technically redundant (i.e. implied by other properties in the specification), but there is some value in testing them anyway:
- They may be more efficient than full functional correctness tests, consuming less computing resources to test.
- They may be more fine-grained to give better test coverage than random inputs for full functional correctness tests.
- They provide a good sanity check to the full functional correctness properties.
- Sometimes full functional correctness is not easily computable but tests of weaker properties are.
These redundant properties include unit tests. We can (and should) combine both approaches!
Lazy Evaluation
It never evaluate anything unless it has to
1 | sumTo :: Integer -> Integer |
This crashes when given a large number. Why? Because of the growing stack frame.
1 | sumTo' :: Integer -> Integer -> Integer |
This still crashes when given a large number. Why?
This is called a space leak, and is one of the main drawbacks of Haskell’s lazy evaluation method.
Haskell is lazily evaluated, also called call-by-need.
This means that expressions are only evaluated when they are needed to compute a result for the user.
We can force the previous program to evaluate its accumulator by using a bang pattern, or the primitive operation seq:
1 |
|
Advantages
Lazy Evaluation has many advantages:
- It enables equational reasoning even in the presence of partial functions and non-termination
- It allows functions to be decomposed without sacrificing efficiency, for example: minimum = head . sort is, depending on sorting algorithm, possibly O(n).
- It allows for circular programming and infinite data structures, which allow us to express more things as pure functions.
Infinite Data Structures
Laziness lets us define data structures that extend infinitely. Lists are a common example, but it also applies to trees or any user-defined data type:
1 | ones = 1 : ones |
Many functions such as take, drop, head, tail, filter and map work fine on infinite lists.
1 | naturals = 0 : map (1+) naturals |
Data Invariants and ADTs
Structure of a Module
A Haskell program will usually be made up of many modules, each of which exports one or more data types.
Typically a module for a data type X will also provide a set of functions, called operations, on X.
- to construct the data type: c :: · · · → X
- to query information from the data type: q :: X → · · ·
- to update the data type: u :: · · · X → X
A lot of software can be designed with this structure.
Example:
1 | module Dictionary |
Data Invariants
Data invariants are properties that pertain to a particular data type. Whenever we use operations on that data type, we want to know that our data invariants are maintained.
For a given data type X, we define a wellformedness predicate
$$
\text{wf :: X → Bool}
$$
For a given value x :: X, wf x returns true iff our data invariants hold for the value x
For each operation, if all input values of type X satisfy wf, all output values will satisfy wf.
In other words, for each constructor operation c :: · · · → X, we must show wf (c · · ·), and for each update operation u :: X → X we must show wf x =⇒ wf(u x)
Abstract Data Types
An abstract data type (ADT) is a data type where the implementation details of the type and its associated operations are hidden.
1 | newtype Dict |
If we don’t have access to the implementation of Dict, then we can only access it via the provided operations, which we know preserve our data invariants. Thus, our data invariants cannot be violated if this module is correct.
In general, abstraction is the process of eliminating detail.
The inverse of abstraction is called refinement.
Abstract data types like the dictionary above are abstract in the sense that their implementation details are hidden, and we no longer have to reason about them on the level of implementation.
Validation
Suppose we had a sendEmail function
1 | sendEmail :: String -- email address |
It is possible to mix the two String arguments, and even if we get the order right, it’s possible that the given email address is not valid.
We could define a tiny ADT for validated email addresses, where the data invariant is that the contained email address is valid:
1 | module EmailADT(Email, checkEmail, sendEmail) |
The only way (outside of the EmailADT module) to create a value of type Email is to use checkEmail.
checkEmail is an example of what we call a smart constructor: a constructor that enforces data invariants.
Data Refinement
Reasoning about ADTs
Consider the following, more traditional example of an ADT interface, the unbounded queue:
1 | data Queue |
We could try to come up with properties that relate these functions to each other without reference to their implementation, such as:
dequeue (enqueue x emptyQueue) == emptyQueue
However these do not capture functional correctness (usually).
Models for ADTs
We could imagine a simple implementation for queues, just in terms of lists:
1 | emptyQueueL = [] |
But this implementation is O(n) to enqueue! Unacceptable!
However!(This is out mental model)
This is a dead simple implementation, and trivial to see that it is correct. If we make a better queue implementation, it should always give the same results as this simple one. Therefore: This implementation serves as a functional correctness specification for our Queue type!
Refinement Relations
The typical approach to connect our model queue to our Queue type is to define a relation, called a refinement relation, that relates a Queue to a list and tells us if the two structures represent the same queue conceptually:
1 | rel :: Queue -> [Int] -> Bool |
Abstraction Functions
These refinement relations are very difficult to use with QuickCheck because the rel fq lq preconditions are very hard to satisfy with randomly generated inputs. For this example, it’s a lot easier if we define an abstraction function that computes the corresponding abstract list from the concrete Queue.
1 | toAbstract :: Queue → [Int] |
Conceptually, our refinement relation is then just:
1 | \fq lq → absfun fq == lq |
However, we can re-express our properties in a much more QC-friendly format
1 | import Test.QuickCheck |
Data Refinement
These kinds of properties establish what is known as a data refinement from the abstract, slow, list model to the fast, concrete Queue implementation.
Refinement and Specifications
In general, all functional correctness specifications can be expressed as:
- all data invariants are maintained, and
- the implementation is a refinement of an abstract correctness model.
There is a limit to the amount of abstraction we can do before they become useless for testing (but not necessarily for proving).
Effects
Effects are observable phenomena from the execution of a program.
Internal vs. External Effects
External Observability
An external effect is an effect that is observable outside the function. Internal effects are not observable from outside.
Example
Console, file and network I/O; termination and non-termination; non-local control flow; etc.
Are memory effects external or internal?
Depends on the scope of the memory being accessed. Global variable accesses are external.
Purity
A function with no external effects is called a pure function.
A pure function is the mathematical notion of a function. That is, a function of type a -> b is fully specified by a mapping from all elements of the domain type a to the codomain type b.
Consequences:
- Two invocations with the same arguments result in the same value.
- No observable trace is left beyond the result of the function.
- No implicit notion of time or order of execution.
Haskell Functions
Haskell functions are technically not pure.
They can loop infinitely.
They can throw exceptions (partial functions)
They can force evaluation of unevaluated expressions.
Caveat
Purity only applies to a particular level of abstraction. Even ignoring the above, assembly instructions produced by GHC aren’t really pure.
Despite the impurity of Haskell functions, we can often reason as though they are pure. Hence we call Haskell a purely functional language.
The Danger of Implicit Side Effects
- They introduce (often subtle) requirements on the evaluation order.
- They are not visible from the type signature of the function.
- They introduce non-local dependencies which is bad for software design, increasing coupling.
- They interfere badly with strong typing, for example mutable arrays in Java, or reference types in ML.
We can’t, in general, reason equationally about effectful programs!
Can we program with pure functions?
Typically, a computation involving some state of type s and returning a result of type a can be expressed as a function:
1 | s -> (s, a) |
Rather than change the state, we return a new copy of the state.
All that copying might seem expensive, but by using tree data structures, we can usually reduce the cost to an O(log n) overhead.
State
State Passing
1 | data Tree a = Branch a (Tree a) (Tree a) | Leaf |
Let’s use a data type to simplify this!
State
1 | newtype State s a = A procedure that, manipulating some state of type s, returns a |
Example
1 | {- |
IO
A procedure that performs some side effects, returning a result of type a is written as IO a.
IO a is an abstract type. But we can think of it as a function:
RealWorld -> (RealWorld, a)
(that’s how it’s implemented in GHC)
1 | (>>=) :: IO a -> (a -> IO b) -> IO b |
Infectious IO
We can convert pure values to impure procedures with pure:
1 | pure :: a -> IO a |
But we can’t convert impure procedures to pure values
The only function that gets an a from an IO a is >>=:
1 | (>>=) :: IO a -> (a -> IO b) -> IO b |
But it returns an IO procedure as well.
If a function makes use of IO effects directly or indirectly, it will have IO in its type!
Haskell Design Strategy
We ultimately “run” IO procedures by calling them from main:
1 | main :: IO () |
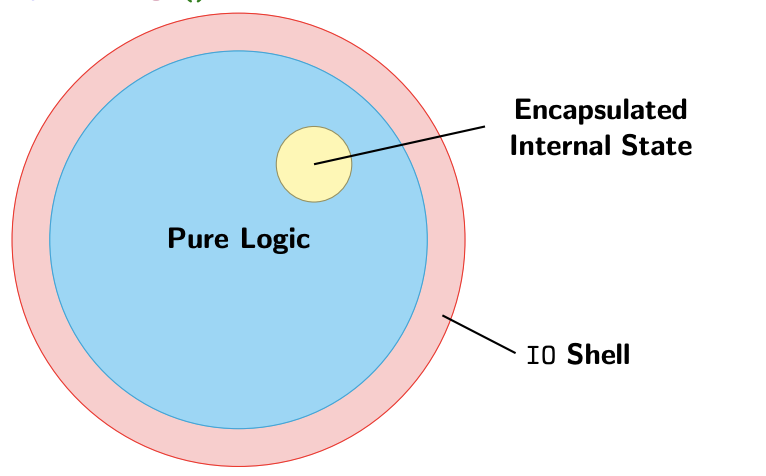
Example
1 | -- Given an input number n, print a triangle of * characters of base width n. |
1 | {- |
Benefits of an IO Type
- Absence of effects makes type system more informative:
- A type signatures captures entire interface of the function
- All dependencies are explicit in the form of data dependencies.
- All dependencies are typed
- It is easier to reason about pure code and it is easier to test
- Testing is local, doesn’t require complex set-up and tear-down.
- Reasoning is local, doesn’t require state invariants
- Type checking leads to strong guarantees.
Mutable Variables
We can have honest-to-goodness mutability in Haskell, if we really need it, using IORef.
1 | data IORef a |
Example
1 | import Data.IORef |
Mutable Variables, Locally
Something like averaging a list of numbers doesn’t require external effects, even if we use mutation internally.
1 | data STRef s a |
The extra s parameter is called a state thread, that ensures that mutable variables don’t leak outside of the ST computation.
The ST type is not assessable in this course, but it is useful sometimes in Haskell programming.
QuickChecking Effects
QuickCheck lets us test IO (and ST) using this special property monad interface:
1 | monadicIO :: PropertyM IO () -> Property |
Do notation and similar can be used for PropertyM IO procedures just as with State s and IO procedures.
Example
1 | -- GNU Factor |
Functor
Recall the type class defined over type constructors called Functor.
We’ve seen instances for lists, Maybe, tuples and functions.
Other instances include:
- IO (how?)
- States (how?)
- Gen
1 | ioMap :: (a -> b) -> IO a -> IO b |
QuickCheck Generators
1 | {- |
Applicative Functors
Binary Functions
Suppose we want to look up a student’s zID and program code using these functions:
1 | lookupID :: Name -> Maybe ZID |
How can we combine these functions to get a function of type Name -> Maybe StudentRecord?
1 | lookupRecord :: Name -> Maybe StudentRecord |
Binary Map?
We could imagine a binary version of the maybeMap function:
1 | maybeMap2 :: (a -> b -> c) |
But then, we might need a trinary version.
1 | maybeMap3 :: (a -> b -> c -> d) |
Or even a 4-ary version, 5-ary, 6-ary. . . this would quickly become impractical!
Using Functor?
Using fmap gets us part of the way there:
1 | lookupRecord' :: Name -> Maybe (Program -> StudentRecord) |
But, now we have a function inside a Maybe.
Applicative
This is encapsulated by a subclass of Functor called Applicative.
1 | class Functor f => Applicative f where |
Maybe is an instance, so we can use this for lookupRecord:
1 | lookupRecord :: Name -> Maybe StudentRecord |
Using Applicative
In general, we can take a regular function application:
$$
\text{f a b c d}
$$
And apply that function to Maybe (or other Applicative) arguments using this pattern (where <*> is left-associative):
$$
\text{pure f <*> ma <*> mb <*> mc <*> }
$$
Relationship to Functor
All law-abiding instances of Applicative are also instances of Functor, by defining:
1 | fmap f x = pure f <*> x |
Sometimes this is written as an infix operator, <$>, which allows us to write:
1 | pure f <*> ma <*> mb <*> mc <*> md |
Applicative laws
1 | -- Identity |
Example
1 | type Name = String |
Functor Laws for Applicative
These are proofs not Haskell code:
1 | fmap f x = pure f <*> x |
Applicative Lists
There are two ways to implement Applicative for lists:
1 | (<*>) :: [a -> b] -> [a] -> [b] |
- Apply each of the given functions to each of the given arguments, concatenating all the results
- Apply each function in the list of functions to the corresponding value in the list of arguments
The second one is put behind a newtype (ZipList) in the Haskell standard library.
1 | pureZ :: a -> [a] |
Other instances
QuickCheck generators: Gen
1 | data Concrete = C [Char] [Char] |
Functions: ((->) x
The
Applicativeinstance for functions lets us pass the same argument into multiple functions without repeating ourselves.
1 | instance Applicative ((->) x) where |
Tuples: ((,) x)
We can’t implement pure without an extra constraint!
The tuple instance for
Applicativelets us combine secondary outputs from functions into one secondary output without manually combining them.
1 | instance Functor ((,) x) where |
It requires Monoid here to combine the values, and to provide a default value for pure.
1 | f :: A -> (Log, B) |
IO and State s
1 | instance Applicative IO where |
Monads
Monads are types m where we can sequentially compose functions of the form a -> m b
1 | class Applicative m => Monad m where |
Sometimes in old documentation the function return is included here, but it is just an alias for pure. It has nothing to do with return as in C/Java/Python etc.
Example
1 | -- Maybe Monad |
Monad Law
We can define a composition operator with (>>=):
1 | (<=<) :: (b -> m c) -> (a -> m b) -> (a -> m c) |
Monad Laws
1 | f <=< (g <=< x) == (f <=< g) <=< x -- associativity |
These are similar to the monoid laws, generalised for multiple types inside the monad. This sort of structure is called a category in mathematics.
Relationship to Applicative
All Monad instances give rise to an Applicative instance, because we can define <*> in terms of >>=.
1 | mf <*> mx = mf >>= \f -> mx >>= \x -> pure (f x) |
This implementation is already provided for Monads as the ap function in Control.Monad
Do notation
Working directly with the monad functions can be unpleasant. As we’ve seen, Haskell has some notation to increase niceness:
1 | do x <- y |
Examples
1 | {- |
Static Assurance with Types
Static Assureance
Methods of Assurance
Static means of assurance analyse a program without running it.
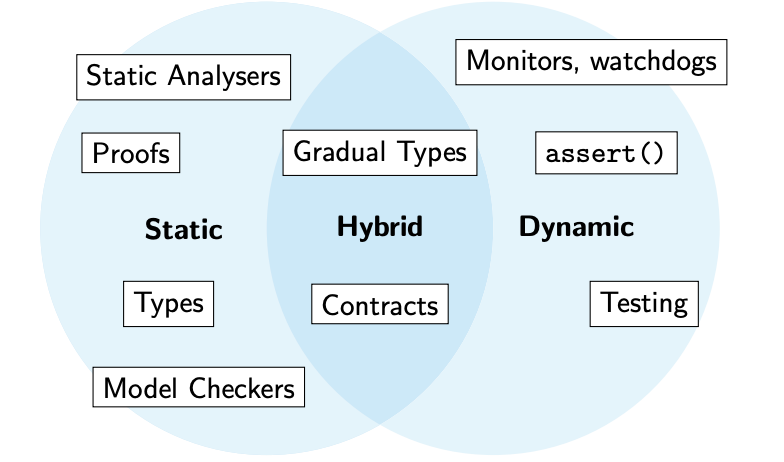
Static vs. Dynamic
Static checks can be exhaustive.
Exhaustivity
An exhaustive check is a check that is able to analyse all possible executions of a program.
- However, some properties cannot be checked statically in general (halting problem), or are intractable to feasibly check statically (state space explosion).
- Dynamic checks cannot be exhaustive, but can be used to check some properties where static methods are unsuitable.
Compiler Integration
Most static and all dynamic methods of assurance are not integrated into the compilation process.
- You can compile and run your program even if it fails tests
- You can change your program to diverge from your model checker model.
- Your proofs can diverge from your implementation.
Types
Because types are integrated into the compiler, they cannot diverge from the source code. This means that type signatures are a kind of machine-checked documentation for your code.
Types are the most widely used kind of formal verification in programming today.
- They are checked automatically by the compiler.
- They can be extended to encompass properties and proof systems with very high expressivity (covered next week).
- They are an exhaustive analysis
Phantom Types
A type parameter is phantom if it does not appear in the right hand side of the type definition.
1 | newtype Size x = S Int |
Lets examine each one of the following use cases:
- We can use this parameter to track what data invariants have been established about a value.
- We can use this parameter to track information about the representation (e.g. units of measure).
- We can use this parameter to enforce an ordering of operations performed on these values (type state).
Validation
Suppose we have
1 | data UG -- empty type |
We can define a smart constructor that specialises the type parameter:
1 | sid :: Int -> Either (StudentID UG) |
Define functions:
1 | enrolInCOMP3141 :: StudentID UG -> IO () |
Units of Measure
1 | data Kilometres |
Type State
1 | {- |
Linearity and Type State
The previous code assumed that we didn’t re-use old Sockets:
1 | send2 :: Socket Ready -> String -> String |
Linear type systems can solve this, but not in Haskell (yet)
Datatype Promotion
1 | data UG |
Defining empty data types for our tags is untyped. We can have StudentID UG, but also StudentID String.
The DataKinds language extension lets us use data types as kinds:
1 |
|
GADTs
Untyped Evaluator
1 | data Expr t = BConst Bool |
GADTs
Generalised Algebraic Datatypes (GADTs) is an extension to Haskell that, among other things, allows data types to be specified by writing the types of their constructors.
1 |
|
When combined with the type indexing trick of phantom types, this becomes very powerful!
Typed Evaluator
There is now only one set of precisely-typed constructors.
1 |
|
Lists
We could define our own list type using GADT syntax as follows:
1 | data List (a :: *) :: * where |
We will constrain the domain of these functions by tracking the length of the list on the type level.
Vectors
1 |
|
Tradeoffs
The benefits of this extra static checking are obvious, however:
- It can be difficult to convince the Haskell type checker that your code is correct, even when it is.
- Type-level encodings can make types more verbose and programs harder to understand.
- Sometimes excessively detailed types can make type-checking very slow, hindering productivity
Pragmatism
We should use type-based encodings only when the assurance advantages outweigh the clarity disadvantages.
The typical use case for these richly-typed structures is to eliminate partial functions from our code base.
If we never use partial list functions, length-indexed vectors are not particularly useful
Theory of Types
Logic
We can specify a logical system as a _deductive system_ by providing a set of rules and axioms that describe how to prove various connectives.
Natural Deduction
A way we can specify logic
Each connective typically has introduction and elimination rules. For example, to prove an implication A → B holds, we must show that B holds assuming A. This introduction rule is written as:
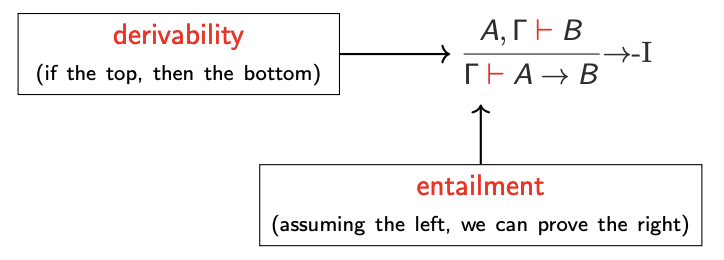
More rules
Implication also has an elimination rule, that is also called modus ponens:
$$\frac{\ulcorner \vdash A\rightarrow B \space\space\space\space\space\space\space\space\ulcorner \vdash A}{\ulcorner \vdash B}\rightarrow-E$$
Conjunction (and) has an introduction rule that follows our intuition:
$$
\frac{\ulcorner \vdash A\space\space\space\space\space\space\space\space\space \ulcorner \vdash B}{\ulcorner \vdash A\land B}\land-I_1
$$
It has two elimination rules:
$$
\frac{\ulcorner \vdash A\land B}{\ulcorner \vdash A}\land-E_1\space\space\space\space\space\space\space\space\space\space\frac{\ulcorner \vdash A\land B}{\ulcorner \vdash B}\land-E_2
$$
Disjunction (or) has two introduction rules:
$$
\frac{\ulcorner \vdash A}{\ulcorner \vdash A\lor B}\land-I_1\space\space\space\space\space\space\space\space\space\space\frac{\ulcorner \vdash A}{\ulcorner \vdash A\lor B}\land-I_2
$$
Disjunction elimination is a little unusual:
$$
\frac{\ulcorner \vdash A\lor B\space\space\space\space\space\space\space A,\ulcorner \vdash P \space\space\space\space\space\space\space B,\ulcorner \vdash P}{\ulcorner \vdash P}\lor-E
$$
The true literal, written T, has only an introduction:
$$
\frac{}{\ulcorner \vdash \top}
$$
And false, written ⊥, has just elimination (ex falso quodlibet):
$$
\frac{\ulcorner \vdash \bot}{\ulcorner \vdash P}
$$
Typically we just define:
$$
\neg A \equiv(A\rightarrow\bot)
$$
Constructive Logic
The logic we have expressed so far does not admit the law of the excluded middle:
$$
P\lor\neg P
$$
Or the equivalent double negation elimination:
$$
(\neg\neg P)\rightarrow P
$$
This is because it is a constructive logic that does not allow us to do proof by contradiction.
Typed Lambda Calculus
Boiling Haskell Down
The theoretical properties we will describe also apply to Haskell, but we need a smaller language for demonstration purposes.
- No user-defined types, just a small set of built-in types.
- No polymorphism (type variables)
- Just lambdas (λx.e) to define functions or bind variables.
This language is a very minimal functional language, called the simply typed lambda calculus, originally due to Alonzo Church.
Our small set of built-in types are intended to be enough to express most of the data types we would otherwise define.
We are going to use logical inference rules to specify how expressions are given types (typing rules).
Function Types
We create values of a function type A → B using lambda expressions:
$$
\frac{x :: A, \ulcorner\vdash e::B}{\ulcorner\vdash\lambda x.e::A\rightarrow B}
$$
The typing rule for function application is as follows:
$$
\frac{\ulcorner\vdash e_1:: A\rightarrow B\space\space\space\space\space\space\space\space \ulcorner\vdash e_2::A}{\ulcorner\vdash e_1 e_2:: B}
$$
Composite Data Types
In addition to functions, most programming languages feature ways to compose types together to produce new types, such as: Classes, Tuples, Structs, Unions, Records…
Product Types
For simply typed lambda calculus, we will accomplish this with tuples, also called product types. (A, B)
We won’t have type declarations, named fields or anything like that. More than two values can be combined by nesting products, for example a three dimensional vector:
$$
\text{(Int, (Int, Int))}
$$
Constructors and Eliminators
We can construct a product type the same as Haskell tuples:
$$
\frac{\ulcorner\vdash e_1:: A\space\space\space\space\space\space\space\space \ulcorner\vdash e_2::B}{\ulcorner\vdash(e_1, e_2):: (A, B)}
$$
The only way to extract each component of the product is to use the fst and snd eliminators:
$$
\frac{\ulcorner\vdash e:: (A,B)}{\ulcorner\vdash \text{fst }e::A}\space\space\space\space\space\space\space\space \frac{\ulcorner\vdash e:: (A,B)}{\ulcorner\vdash \text{snd }e::B}
$$
Unit Types
Currently, we have no way to express a type with just one value. This may seem useless at first, but it becomes useful in combination with other types. We’ll introduce the unit type from Haskell, written (), which has exactly one inhabitant, also written ():
$$
\frac{}{\ulcorner\vdash ():: ()}
$$
Disjunctive Composition
We can’t, with the types we have, express a type with exactly three values.
1 | data TrafficLight = Red | Amber | Green |
In general we want to express data that can be one of multiple alternatives, that contain different bits of data.
1 | type Length = Int |
Sum Types
We’ll build in the Haskell Either type to express the possibility that data may be one of two forms.
$$
\text{Either } A \space B
$$
These types are also called sum types.
Our TrafficLight type can be expressed (grotesquely) as a sum of units:
$$
\text{TrafficLight } \simeq \text{Either () (Either () ())}
$$
Constructors and Eliminators for Sums
To make a value of type Either A B, we invoke one of the two constructors:
$$
\frac{\ulcorner\vdash e:: A}{\ulcorner\vdash \text{Left }e::\text{Either }A\space B} \space\space\space\space \space\space\space\space \frac{\ulcorner\vdash e:: B}{\ulcorner\vdash \text{Right }e::\text{Either }A\space B}
$$
We can branch based on which alternative is used using pattern matching:
$$
\frac{\ulcorner\vdash e::\text{Either }A\space B\space\space\space \space \space\space\space\space x::A,\ulcorner\vdash e_1::P\space \space\space\space\space\space\space\space y::B,\ulcorner\vdash e_2::P}{\ulcorner\vdash (\textbf{case }e\textbf{ of}\text{ Left x}\rightarrow e_1; \text{ Right y}\rightarrow e_2)::P}
$$
Example
Our traffic light type has three values as required:
$$
\begin{align*}
\text{TrafficLight } &\simeq \text{Either () (Either () ())}\\
\text{Red } &\simeq \text{Left ()}\\
\text{Amber } &\simeq \text{Right (Left ())}\\
\text{Green } &\simeq \text{Right (Right (Left ()}\\
\end{align*}
$$
The Empty Type
We add another type, called Void, that has no inhabitants. Because it is empty, there is no way to construct it.
We do have a way to eliminate it, however:
$$
\frac{\ulcorner\vdash e::\text{Void}}{\ulcorner\vdash \text{absurd }e::P}
$$
If I have a variable of the empty type in scope, we must be looking at an expression that will never be evaluated. Therefore, we can assign any type we like to this expression, because it will never be executed.
Gathering Rules
$$
\frac{\ulcorner\vdash e::\text{Void}}{\ulcorner\vdash \text{absurd }e::P}\space\space\space\space\space\space\frac{}{\ulcorner\vdash ():: ()}\\
\frac{\ulcorner\vdash e:: A}{\ulcorner\vdash \text{Left }e::\text{Either }A\space B} \space\space\space\space \space\space\space\space \frac{\ulcorner\vdash e:: B}{\ulcorner\vdash \text{Right }e::\text{Either }A\space B}\\
\frac{\ulcorner\vdash e::\text{Either }A\space B\space\space\space \space \space\space\space\space x::A,\ulcorner\vdash e_1::P\space \space\space\space\space\space\space\space y::B,\ulcorner\vdash e_2::P}{\ulcorner\vdash (\textbf{case }e\textbf{ of}\text{ Left x}\rightarrow e_1; \text{ Right y}\rightarrow e_2)::P}\\
\frac{\ulcorner\vdash e_1:: A\space\space\space\space\space\space \ulcorner\vdash e_2::B}{\ulcorner\vdash(e_1, e_2):: (A, B)}\space\space\space\space\space\space\frac{\ulcorner\vdash e:: (A,B)}{\ulcorner\vdash \text{fst }e::A}\space\space\space\space\space\space\frac{\ulcorner\vdash e:: (A,B)}{\ulcorner\vdash \text{snd }e::B}\\
\frac{\ulcorner\vdash e_1:: A\rightarrow B\space\space\space\space\space\space\ulcorner\vdash e_2::A}{\ulcorner\vdash e_1 e_2::B}\space\space\space\space\space\space\space\frac{x :: A, \ulcorner\vdash e::B}{\ulcorner\vdash\lambda x.e::A\rightarrow B}
$$
Removing Terms. . .
$$
\frac{\ulcorner\vdash\text{Void}}{\ulcorner\vdash P}\space\space\space\space\space\space\frac{}{\ulcorner\vdash ()}\\
\frac{\ulcorner\vdash A}{\ulcorner\vdash\text{Either }A\space B} \space\space\space\space \space\space\space\space \frac{\ulcorner\vdash B}{\ulcorner\vdash\text{Either }A\space B}\\
\frac{\ulcorner\vdash \text{Either }A\space B\space\space\space \space \space\space\space\space A,\ulcorner\vdash P\space \space\space\space\space\space\space\space B,\ulcorner\vdash P}{\ulcorner\vdash P}\\
\frac{\ulcorner\vdash A\space\space\space\space\space\space \ulcorner\vdash B}{\ulcorner\vdash(A, B)}\space\space\space\space\space\space\frac{\ulcorner\vdash (A,B)}{\ulcorner\vdash A}\space\space\space\space\space\space \frac{\ulcorner\vdash (A,B)}{\ulcorner\vdash B}\\
\frac{\ulcorner\vdash A\rightarrow B\space\space\space\space\space\space\ulcorner\vdash A}{\ulcorner\vdash B}\space\space\space\space\space\space\space\frac{ A, \ulcorner\vdash B}{\ulcorner\vdash A\rightarrow B}
$$
This looks exactly like constructive logic! If we can construct a program of a certain type, we have also created a proof of a program
The Curry-Howard Correspondence
This correspondence goes by many names, but is usually attributed to Haskell Curry and William Howard.
It is a very deep result:
| Programming | Logic |
|---|---|
| Types | Propositions |
| Programs | Proofs |
| Evaluation | Proof Simplification |
It turns out, no matter what logic you want to define, there is always a corresponding λ-calculus, and vice versa.
| λ-calculus | Logic |
|---|---|
| Typed λ-Calculus | Constructive Logic |
| Continuations | Classical Logic |
| Monads | Modal Logic |
| Linear Types, Session Types | Linear Logic |
| Region Types | Separation Logic |
Translating
We can translate logical connectives to types and back:
| Types | logical connectives |
|---|---|
| Tuples | Conjuction($\land$) |
| Either | Disjunction (∨) |
| Functions | Implication |
| () | True |
| Void | False |
We can also translate our equational reasoning on programs into proof simplification on proofs!
Proof Simplification
Assuming A $∧$ B, we want to prove B $∧$ A. We have this unpleasant proof:
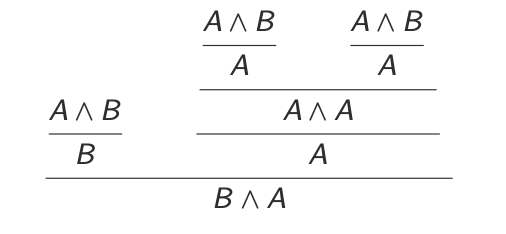
Translating to types, we get: Assuming x :: (A, B), we want to construct (B, A).

We know that
$$
\text{(snd x, snd (fst x, fst x)) = (snd x, fst x)}
$$
Assuming x :: (A, B), we want to construct (B, A).
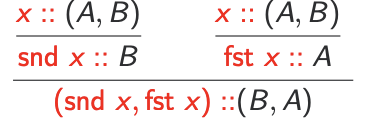
Back to logic:
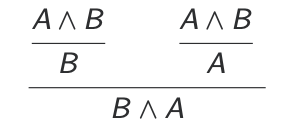
Applications
As mentioned before, in dependently typed languages such as Agda and Idris, the distinction between value-level and type-level languages is removed, allowing us to refer to our program in types (i.e. propositions) and then construct programs of those types (i.e. proofs).
Generally, dependent types allow us to use rich types not just for programming, but also for verification via the Curry-Howard correspondence.
Caveats
All functions we define have to be total and terminating. Otherwise we get an inconsistent logic that lets us prove false things.
Most common calculi correspond to constructive logic, not classical ones, so principles like the law of excluded middle or double negation elimination do not hold.
Algebraic Type Isomorphism
Semiring Structure
These types we have defined form an algebraic structure called a commutative semiring
Laws for Either and Void:
- Associativity: Either (Either A B) C $\simeq$ Either A (Either B C)
- Identity: Either Void A $\simeq$ A
- Commutativity: Either A B $\simeq$ Either B A
Laws for tuples and 1:
- Associativity: ((A, B), C) $\simeq$ (A,(B, C))
- Identity: ((), A) $\simeq$ A
- Commutativity: (A, B) $\simeq$ (B, A)
Combining the two:
- Distributivity: (A, Either B C) $\simeq$ Either (A, B) (A, C)
- Absorption: (Void, A) $\simeq$ Void
What does $\simeq$ mean here? It’s more than logical equivalence. Distinguish more things.
Isomorphism
Two types A and B are isomorphic, written A $\simeq$ B, if there exists a bijection between them. This means that for each value in A we can find a unique value in B and vice versa.
Example:
1 | data Switch = On Name Int |
Can be simplified to the isomorphic (Name, Maybe Int).
Generic Programming
Representing data types generically as sums and products is the foundation for generic programming libraries such as GHC generics. This allows us to define algorithms that work on arbitrary data structures.
Polymorphism and Parametricty
Type Quantifiers
Consider the type of fst:
1 | fst :: (a,b) -> a |
This can be written more verbosely as:
1 | fst :: forall a b. (a,b) -> a |
Or, in a more mathematical notation:
$$
\text{fst}::\forall a\space b(a, b)\rightarrow a
$$
This kind of quantification over type variables is called parametric polymorphism or just polymorphism for short.
(It’s also called generics in some languages, but this terminology is bad)
Curry-Howard
The type quantifier ∀ corresponds to a universal quantifier ∀, but it is not the same as the ∀ from first-order logic. What’s the difference?
First-order logic quantifiers range over a set of individuals or values, for example the natural numbers:
$$
\forall x. x+1 >x
$$
These quantifiers range over propositions (types) themselves. It is analogous to second-order logic, not first-order:
$$
\forall A.\forall B\space A\land B \rightarrow B\land A\\
\forall A.\forall B\space (A, B) \rightarrow (B, A)
$$
The first-order quantifier has a type-theoretic analogue too (type indices), but this is not nearly as common as polymorphism.
Generality
A type A is more general than a type B, often written A $\sqsubseteq$ B, if type variables in A can be instantiated to give the type B.
If we need a function of type Int → Int, a polymorphic function of type ∀a. a → a will do just fine, we can just instantiate the type variable to Int. But the reverse is not true. This gives rise to an ordering.
Example
$$
\text{Int}\rightarrow\text{Int} \sqsupseteq \forall z. z\rightarrow z\sqsupseteq \forall x\space y. x\rightarrow y\sqsupseteq\forall a. a
$$
Constraining Implementations
How many possible total, terminating implementations are there of a function of the following type? Many
$$
\text{Int}\rightarrow\text{Int}
$$
How about this type? 1
$$
\forall a. a\rightarrow a
$$
Polymorphic type signatures constrain implementations.
Parametricity
The principle of parametricity states that the result of polymorphic functions cannot depend on values of an abstracted type.
More formally, suppose I have a polymorphic function g that is polymorphic on type a. If run any arbitrary function f :: a → a on all the a values in the input of g, that will give the same results as running g first, then f on all the a values of the output.
Example:
$$
foo :: ∀a. [a] → [a]
$$
We know that every element of the output occurs in the input. The parametricity theorem we get is, for all f :
$$
\text{foo }\circ(\text{map f}) = (\text{map f})\circ \text{foo}
$$
$$
head :: ∀a. [a] → a\\
\text{ f (head l) = head (map f l)}
$$
$$
(++) :: ∀a. [a] → [a] → [a]\\
\text{map f (a ++ b) = map f a ++ map f b}
$$
$$
concat :: ∀a. [[a]] → [a]\\
\text{map f (concat ls) = concat (map (map f ) ls)}
$$
Higher Order Functions
$$
filter :: ∀a. (a → Bool) → [a] → [a]\\
\text{filter p (map f ls) = map f (filter (p ◦ f ) ls)}
$$
Parametricity Theorems
Follow a similar structure. In fact it can be mechanically derived, using the relational parametricity framework invented by John C. Reynolds, and popularised by Wadler in the famous paper, “Theorems for Free!”1 .
Upshot: We can ask lambdabot on the Haskell IRC channel for these theorems.